Architecture
The architecture is built on the SOIMA framework and extends it with a key innovation: the Full Activation method. Instead of selecting a single Best Matching Unit (BMU) to propagate information, every neuron in the map contributes to the output, weighted by its activation level. This distributes computation across the entire representational space, granting the system emergent generalization capabilities that BMU-based methods cannot achieve.
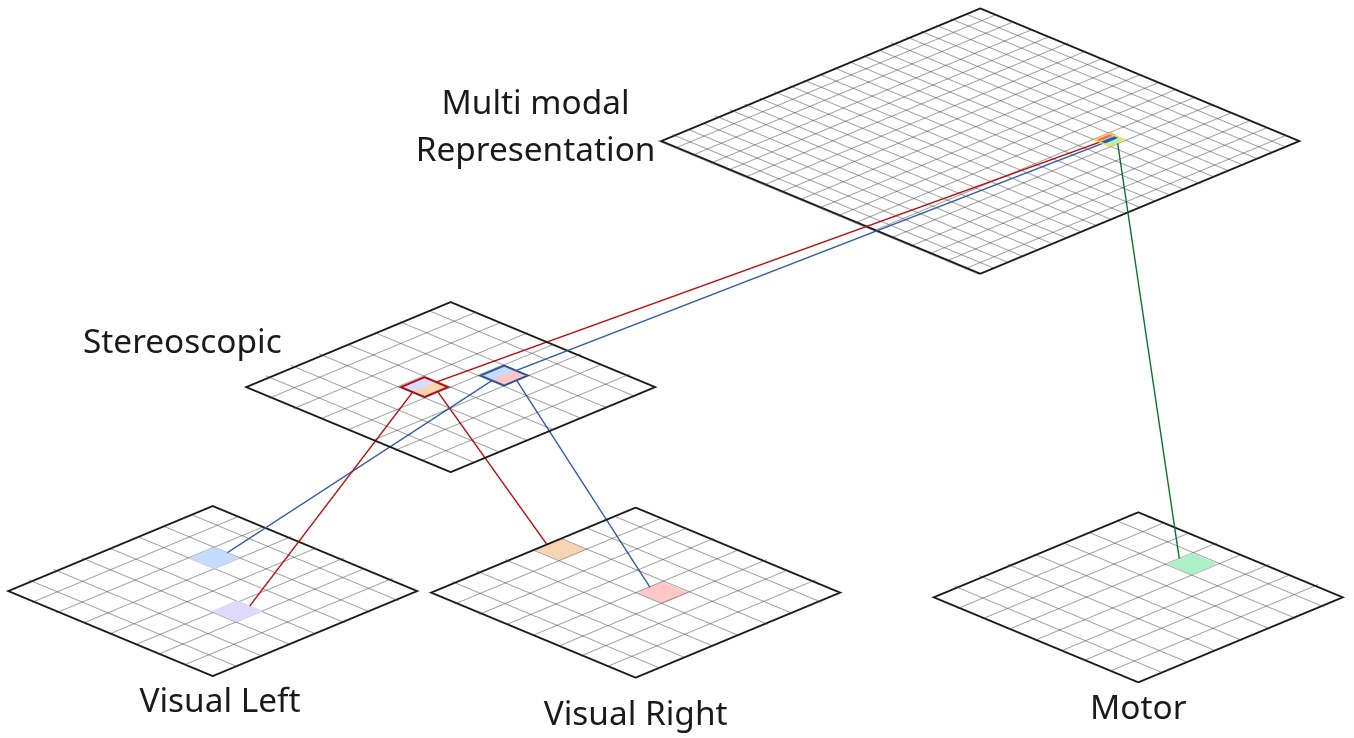
Figure 1. Implemented architecture for visuo-motor coordination. Visual signals from left and right cameras are encoded in independent SOMs, fused stereoscopically, and combined with motor information in the Multimodal Representation (MMR) SOM via Hebbian weights.
The Full Activation propagation for the inverse model proceeds in three steps: stereo activation is computed via element-wise intersection of the two visual streams; both current and goal stereo activations are propagated to the MMR and intersected; and the motor output is obtained by projecting the MMR activation onto the motor SOM.
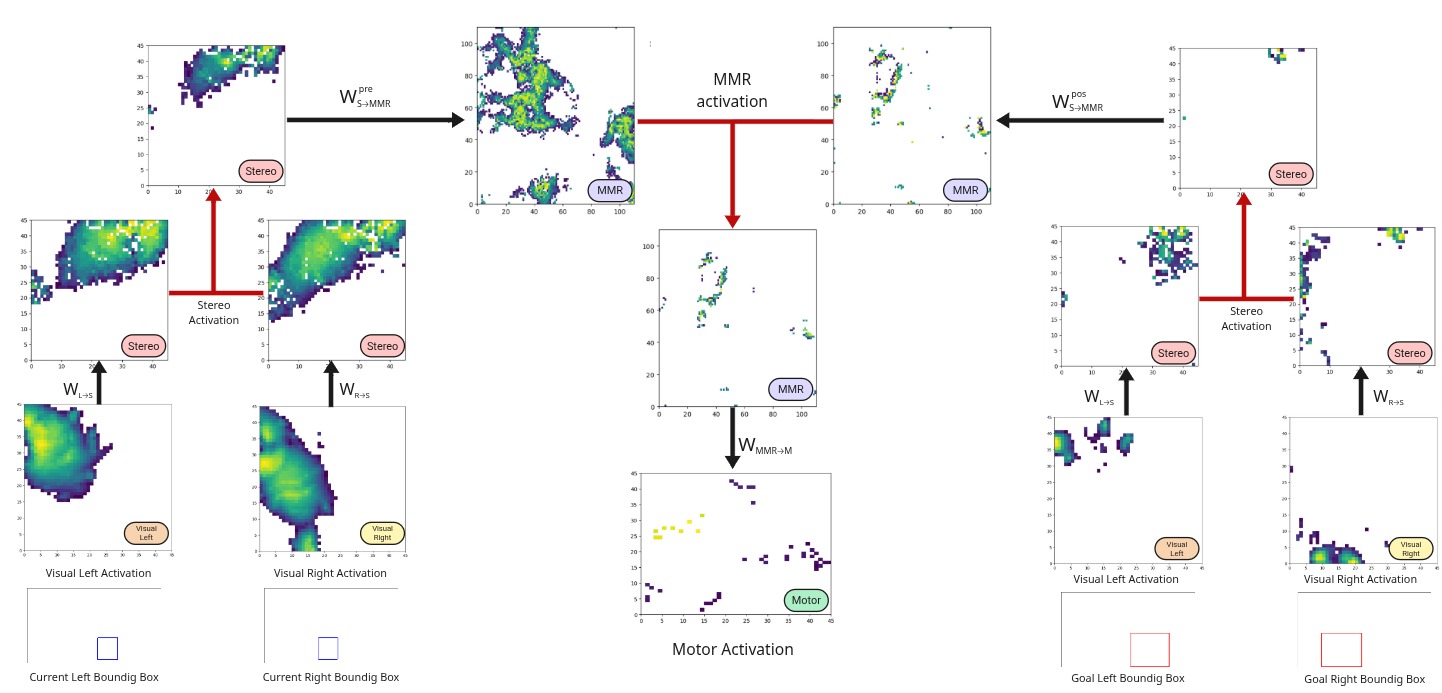
Figure 2. Activation propagation using the Full Activation method (inverse model). Black connections denote propagation via Hebbian weight matrices; red connections indicate element-wise intersection between maps of the same type.
Training Data
The robotic arm is initialized in front of a table with an object of interest (a 5x5 cm cube), and the rendering of synthetic images is used to simulate visual input. The arm then performs a series of completely random movements and records the sensory consequences (motor babbling). If the object leaves the robot's visual field, the arm is reset to a predefined position. To sample the visual experience space as thoroughly as possible, the reset position is not fixed. Instead, two reference configurations are defined, one close to the object and another farther away, and at each reset, the arm is placed at a position interpolated between these two. The object of interest remains fixed in the same position throughout this process. This design choice intentionally limits the variability of the dataset in order to evaluate the system’s generalization capabilities under controlled conditions. The final dataset contains 80k sensorimotor contingencies, corresponding to 80k random motor commands executed by the robotic arm.
Training Data generation process. The robot is performing motor babbling and recording the object's bounding boxes at each time step.
Results
The model is evaluated on 125 object positions arranged in a 5×5×5 cuboid within the workspace — all unseen during training, which was conducted with the object fixed at a single position.
The video shows the final position of the robotic arm for each of the 125 cube positions in the evaluation.
The Full Activation strategy's superiority over Best Match in the pre-grasping task demonstrates that distributing activation across the full map — rather than committing to a single winning neuron — allows the system to generalize to goal configurations it has never explicitly encountered.
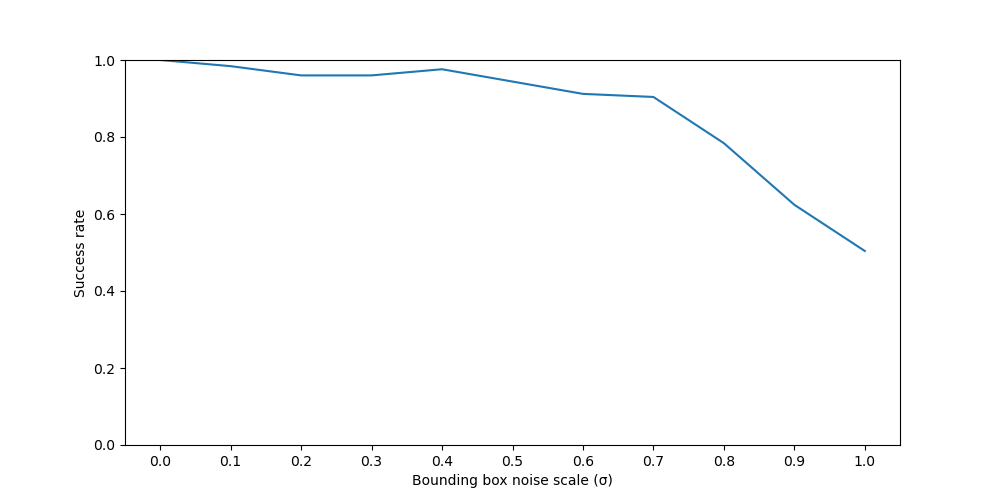
Figure 4. Success rate under increasing levels of visual bounding box noise (σ).
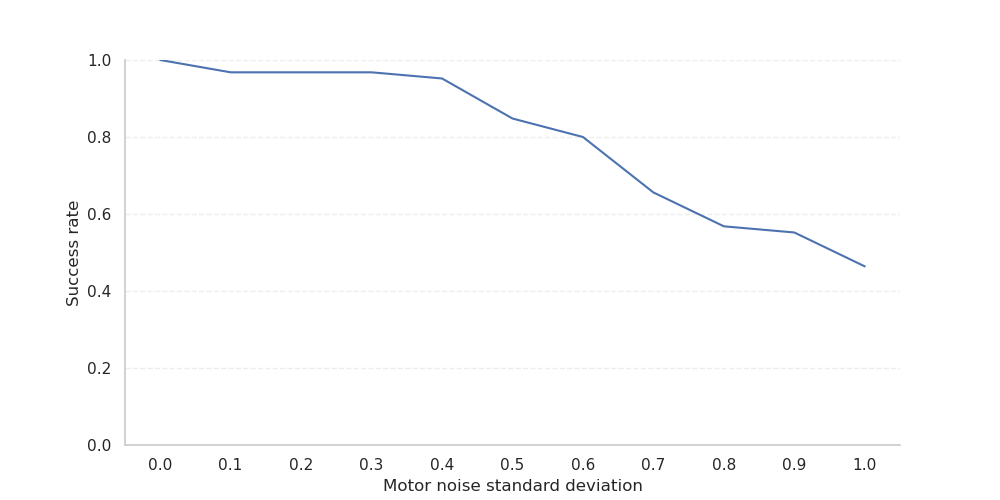
Figure 5. Success rate under increasing levels of multiplicative motor noise.
Fault Detection via Prediction Error
Because the architecture encodes both a forward and an inverse model in the same neural substrate, it can predict the sensory consequences of its own actions before executing them. The discrepancy between predicted and actual sensory state yields a prediction error signal that grows significantly and with statistical robustness under injected noise — suggesting it could serve as an online fault detector for hardware failures or environmental interference.
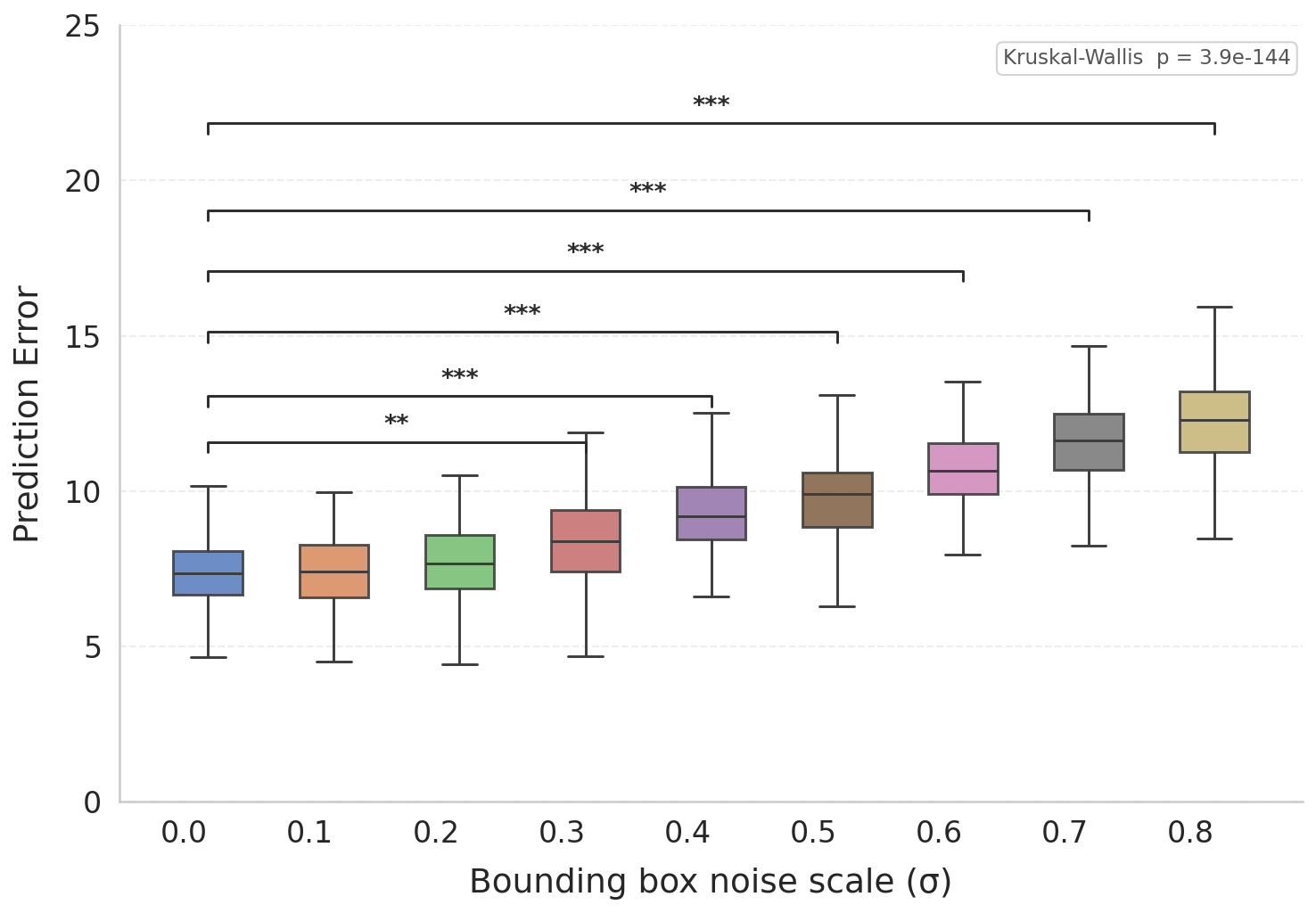
Figure 6. Distribution of prediction errors under increasing visual noise levels. Differences from the baseline are statistically significant (Kruskal-Wallis + Dunn's post-hoc, Holm-corrected). ** p < 0.01 *** p < 0.001.