1Facultad de Ingeniería, Universidad de la República, Montevideo, Uruguay 2Facultad de Ciencias, Universidad de la República, Montevideo, Uruguay 3Centro de Investigación en Ciencias, Universidad Autónoma del Estado de Morelos, Morelos, México
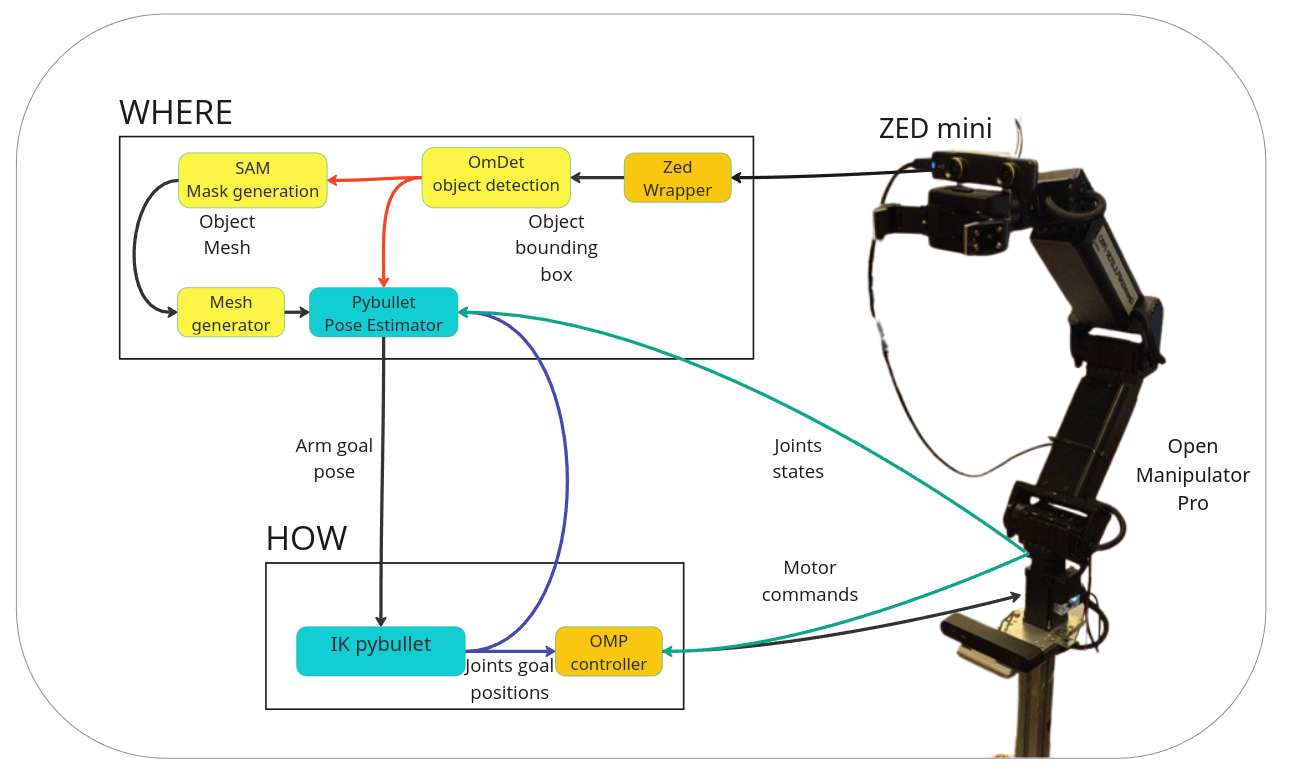
Figure 1. The Guayabo domestic robot (right) and its grasping architecture based on Jeannerod's
What–Where–How taxonomy (left), implemented in ROS2. The Where module is augmented
with an internal PyBullet simulation that generates synthetic perception to correct the object's pose in real time.
Abstract
This paper describes a novel closed-loop manipulation approach based on internal simulation and
synthetic perception rendering. We propose using an internal simulator as a forward model that
builds synthetic perception — the sensory input the simulated robot would receive — which acts
as an error signal to refine the robot's world representation through an inverse model, ultimately
improving its ability to manipulate objects.
We first describe a comprehensive pipeline for open-vocabulary object detection, segmentation,
and 3D modeling tailored for the Guayabo domestic robot. Then, combining concepts from
Intuitive Physics and
Internal Models, we introduce
a novel closed-loop control approach. By using this correction mechanism, the baseline object
grasping method goes from a 54% success rate to 92%.
Method
The pipeline follows Jeannerod's motor control taxonomy, organized into three intercommunicating
modules: What (which object to grasp), Where (object position in space), and
How (motor commands to reach it). The main contribution lives in the Where module.
Object detection uses OmDet, an open-vocabulary detector capable of identifying arbitrary
household objects by name. The detected bounding box is then refined with SAM segmentation
and converted into a 3D mesh via depth information and the Alpha Shapes algorithm. This mesh
is placed inside a PyBullet internal simulation that mirrors the real robot's joint positions at all times.
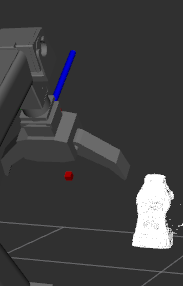
Figure 2. Mesh construction pipeline. A 3×3 grid of points seeds the SAM segmentation mask (a),
which combined with depth data yields a point cloud (b). The Alpha Shapes algorithm produces
the final triangular mesh placed inside the simulator (c).
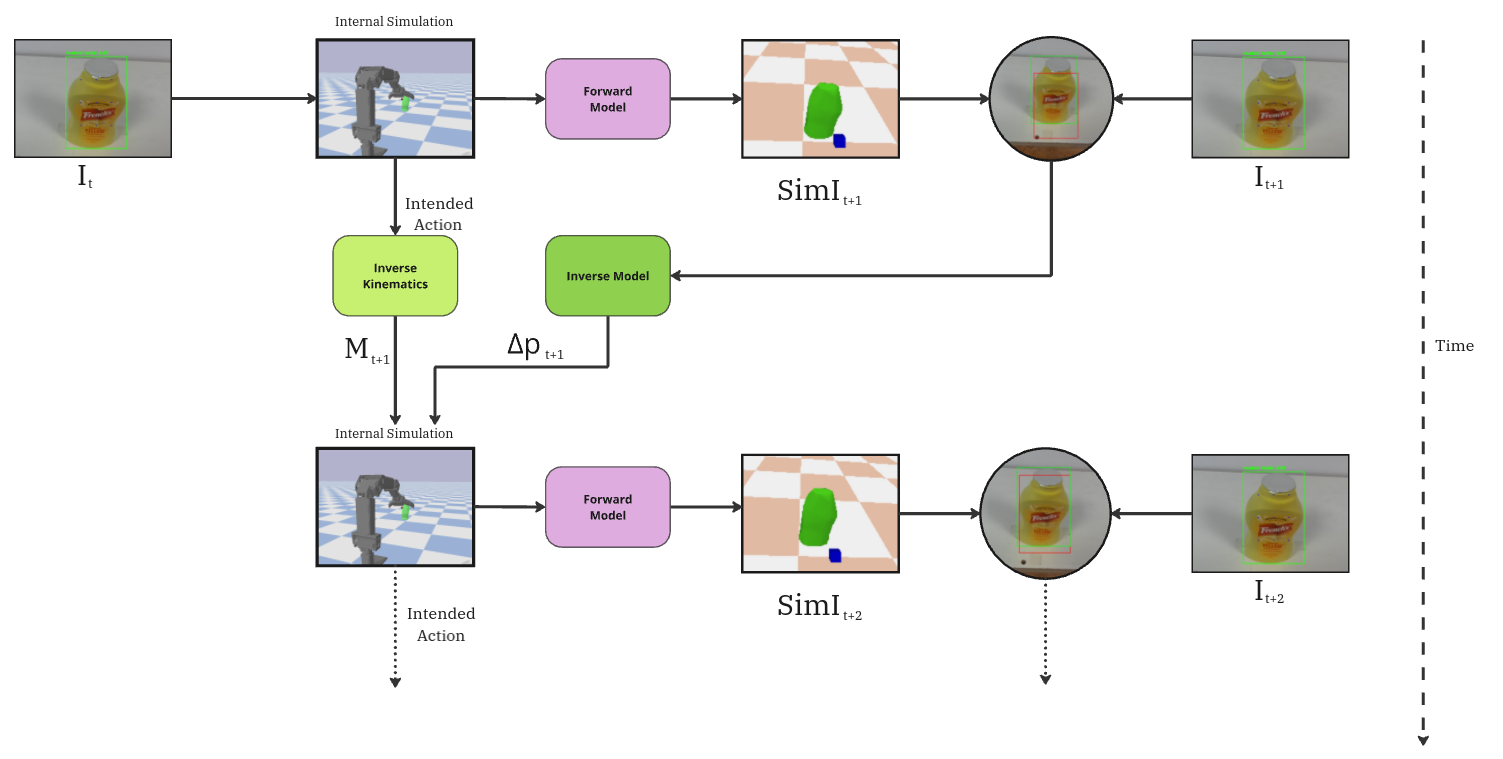
Once the mesh is in simulation, the forward model renders a synthetic camera image and extracts
a simulated bounding box. The discrepancy between the synthetic and real bounding boxes drives
an inverse model that computes a displacement vector Δp, correcting the object's position in the
simulator and closing the feedback loop.
Figure 3. The pose correction loop framed as internal models. The forward model generates
synthetic perception (SimIt+1); its difference from real perception (It+1)
feeds an inverse model that outputs a displacement vector Δpt+1 to correct the
object's simulated position.
Experimental Conditions
Five common household objects (cup, ball, can, marker, mustard bottle) were grasped at
20 positions across a table and shelf, totalling 100 attempts per condition.
A grasp is considered successful only if the robot picks the object up and holds it
for 5 seconds while returning to the home position.
Baseline
54%
Open-loop trajectory in 4 seconds. No pose correction applied.
Always-On Correction
79%
Pose corrected at 30 Hz throughout a 15-second trajectory, with 4 goal updates.
Motion-Aware Correction
92%
Correction triggered only when the arm is static: once at home, once at 80% of trajectory.
Baseline — open-loop, 4 s trajectory.
Always-On Correction — 30 Hz pose correction, 15 s trajectory.
Motion-Aware Correction — correction at rest only.
Both correction conditions significantly outperform the baseline (z-ratio test).
The Always-On approach reaches 79% (z = 3.75, p = 1.8×10−4) and
Motion-Aware reaches 92% (z = 6.05, p = 1.4×10−9).
The gap between the two correction conditions is also statistically significant
(z = 2.61, p = 9.8×10−3), with Motion-Aware outperforming Always-On
due to avoiding synchronization noise from correcting during arm movement.
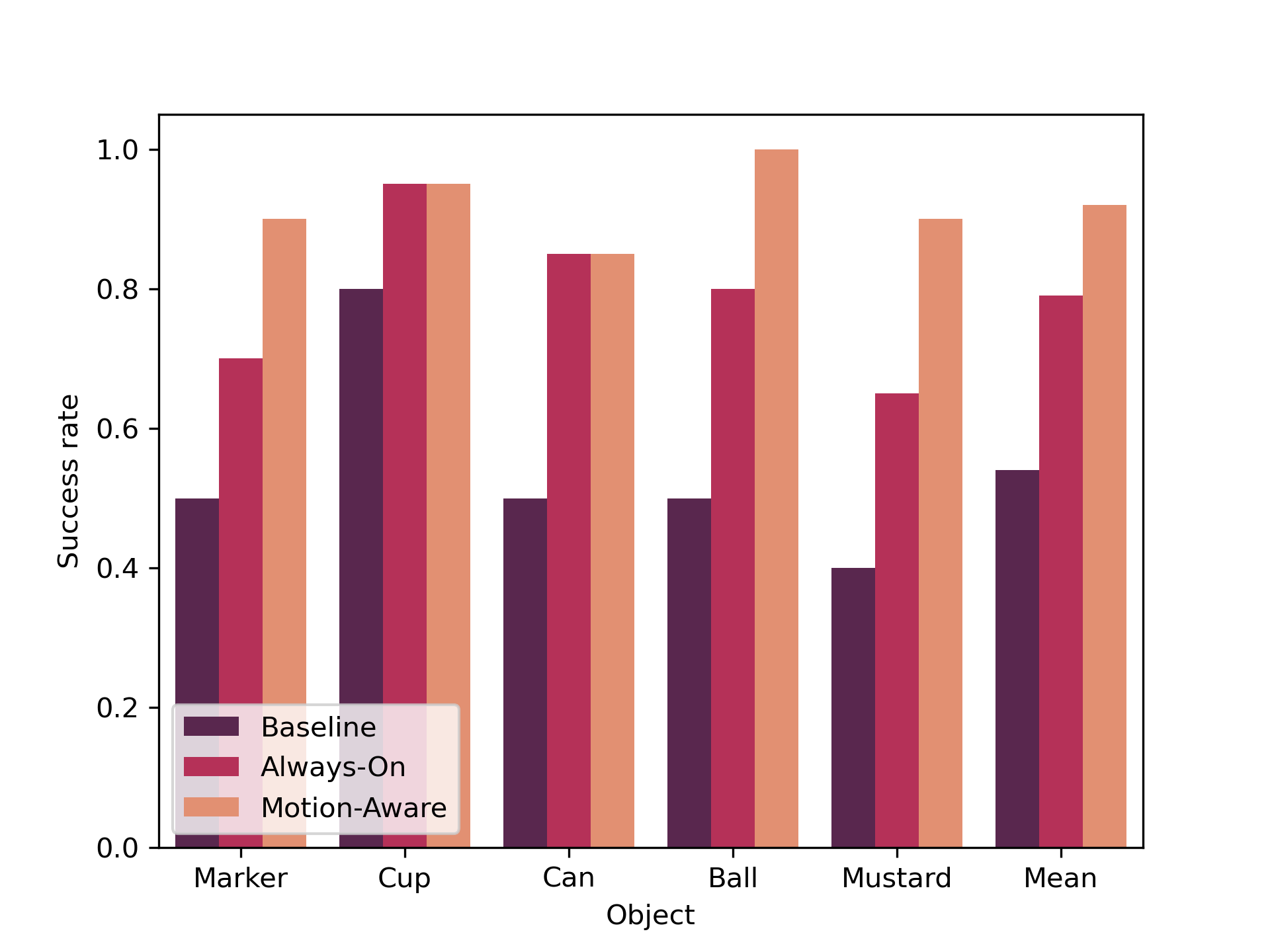
Results
Figure 5. Grasping success rate by object under the three conditions.
Motion-Aware correction consistently outperforms both Baseline and Always-On across all five objects.
The full pipeline — detection, segmentation, modeling, planning, correction, and grasping —
completes in under 30 seconds in every trial. The most time-consuming step is SAM segmentation
(~3 s/iteration when deployed on CPU). In further testing, model acquisition time was reduced
from 15 s to 3 s by dynamically loading relevant models to GPU at execution time.
BibTeX
@inproceedings{barnech2025improving,
title={Improving Object Grasping Through Synthetic Perception-Based Pose Correction in Robotic Manipulation},
author={Barnech, Guillermo Trinidad and Lisboa, Juan Valle and Lara, Bruno and Tejera, Gonzalo},
booktitle={2025 IEEE International Conference on Development and Learning (ICDL)},
pages={1--7},
year={2025},
organization={IEEE}
}