2.1 - Implementación.
La implementación de una imagen es la estructura ( clase ) donde
se almacenan los pixeles con una representación espacial. Es la
forma más clásica e intuitiva de guardar la información.
Esencialmente podemos pensar que tenemos un Array 2D
o 3D de dimensiones n x m , donde cada una
de las celdas contiene un pixel.
Dimensiones e Indexado
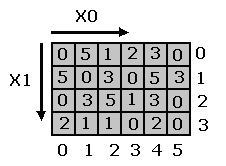
A modo de ejemplo, la figura 2.1.2
muestra un array 2D 6 x 4. Es importante notar dos cosas respecto
al indexado . Primero , todos los índices comienzan
en cero ( 0 ) y van hasta dim - 1. Segundo, las dimensiones de las estructuras
son X0, X1,..., Xn donde X0 indica el número de columnas,
X1 el
de filas, etc. Por lo tanto hay que tener cuidado que
cuando decimos que una imagen es n x m , estamos
diciendo que X0 = n , X1= m.
En el caso de la figura 2.1.2, por ejemplo :
I ( 0 , 0 ) = 0
I ( 2 , 2 ) = 5
I ( 5 , 3 ) = 0
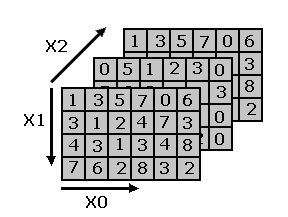
En la figura 1.1.3 vemos un array 3D , en este caso :
I ( 0 , 0 , 0 ) = 1
I ( 4 , 0 , 1 ) = 3
I ( 5 , 3 , 2 ) = 2
Default Pixel
Como la implementación está
parametrizada en el tipo del pixel, es un "template" de PixelType, cuando
se crea la implementación debemos saber con que
valor rellenar la memoria. No podemos poner siempre
ceros por ejemplo , porque esto no tiene sentido cuando
el pixel no es un tipo básico.
Por ejemplo si definimos la clase "Imagen" parametrizada
en la clase "PixelType"
template < class PixelType >
class Imagen
{
PixelType
def_pix; // Tiene una variable interna def_pix
del tipo PixelTYpe
.
.
En el constructor no puedo escribir :
def_pix = 0;
Esto solo funciona si PixelType es
un tipo básico o una clase que tenga definida el operador = a un
entero ( flotante o doble )
Por lo tanto la imagen siempre tiene asociado un pixel
por defecto que debe ser pasado en el constructor. Cuando se crea la implementación
se llena toda la memoria con ese valor de pixel.
El pixel por defecto se usará tambien en muchos
otros algoritmos, que luego veremos
Pixel Case y Escala
No entraremos aquí en detalles sobre los pixeles que rellenan a la imágen, ver Pixels para mas detalles, pero hay dos propiedades de los pixeles que tienen interés representar en la imágen.
Pixel Case
Hay una distinción
entre pixeles simples o escalares ( blaco y negro ) y vectoriales ( colores
por ej ).
Cuando usamos como pixeles a los tipos
básicos de C++ por ejemplo , tenemos una imagen de pixeles
simples, por otro lado cuando usamos
RGB , HSV o alguna otra representación con carácter vectrial,
tendremos una imagen de pixeles vectoriales.
Para ditinguir entre estos casos la
imagen tiene una variable que puede tomar tres valores.
Se definió el enumerado :
PixelCases = { unknown , single , vectorial }
Esta variable debe ser seteada cuando
se crea la implementación , cuando no se la pasa se toma por
defecto el valor unknown ( desconocido
).
El uso de esta variable se explicará
luego , pero vale la pena aclarar que siempre que se conozca el
tipo de pixel conviene setearla ,
ya que de lo contrario no podrán usarse algunos algoritmos de la
biblioteca.
Escala
Cuando se
necesitan hacer medidas sobre la imágen es conveniente tener un
valor para representar
las dimensiones de un pixel. Una sola
variable real será representativa de la escala, como se indica en
la figura 2.1.4. Es decir, en 2D el
pixel es un cuadrado, en 3D un cubo, etc.
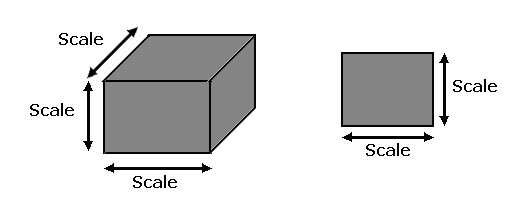
El valor de la escala debe setearse cuando se crea la implementación, por defecto se tomará 1.
Implementaciones
La estructura de herencia de las implementaciones se ilustra en la figura 2.1.1.
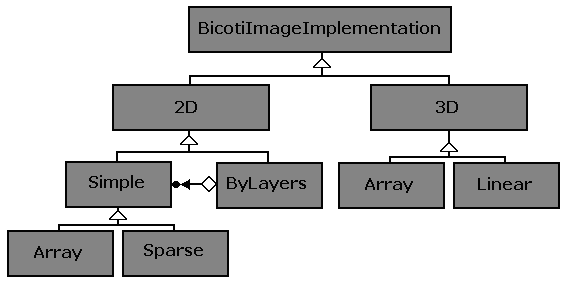
La clase base es abstracta y tiene especializaciones de acuerdo a la dimensión ( 2D , 3D , .. ). También las clases del segundo nivel son abstractas y tienen epecializaciones de acuerdo a la forma como se almacenan en memoria los datos.
By Layers
En 2D , hay una distinción entre
dos formas de reprsentar una imagen. Una representación simple
como se explicó anterirormente
y una por capas ( by layers ) que esencialmente es una agregación
(un colage) de imagenes simples a
diferentes niveles y ubicaciones.
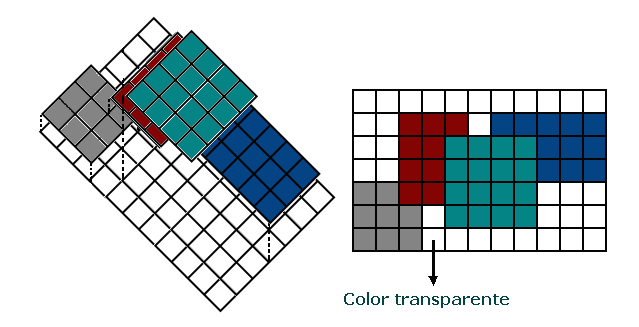
Se define el color de fondo
como un color transparente y luego se superponen sobre el un conjunto de
imagenes de distintas dimensiones
y a distintas profundidades, de forma que las de más alto nivel
prevalecen sobre las de abajo en la
imagen resultante, como se indica en la figura 2.1.5.
Cada imagen simple puede representarse
de varias formas en memoria, nosotros hemos implementado
tres casos :
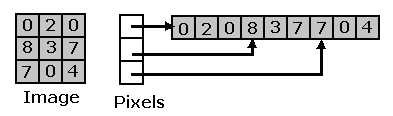
Linear
Toda la memoria se almacena en forma
contigua en memoria. Por ejemplo si tenemos una imagen
2D 3x3 , en memoria se almacenará
un array de 9 pixeles contiguos, como se indica en la
figura 2.1.6.
Internamente se sabe adonde comienzan
filas y columnas.
Se tendrá un array de pixeles
y un array de punteros a pixeles, de esta forma se puede acceder al
elemenmto I ( i , j ) como Pixeles[
i ][ j ].
La ventaja de una representación de este tipo es que produce muy poca fragmentación de memoria.
Array
Se almacenan tantos arrays como filas
se tengan. Por ejemplo si tenemos una imagen 2D 3x4 , se
almacenan 4 arrays de 3 pixeles, como
se muestra en la figura 2.1.7.
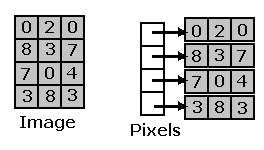
Tendremos en memoria 4 arrays
de 3 pixeles y un array de 4 punteros a pixeles. Se puede acceder
al elemento I ( i , j ) como Pixeles[i][j].
Esta representación produce
más fragmentación que la lineal, pero al necesitar segmentos
más chicos
es menos probable que se rechaze la
solicitud por falta de memoria contigua ( devolviendo un puntero
null cuando se hace un new por ejemplo
)
Sparse
Esta representación es ideal
para ahorrar memoria cuando se usan imágenes muy poco densas, por
ejemplo cuando tienen muchos ceros.
No entraremos aqui en detalles sobre la estructura, ver Sparse
Matrix en las referencias para mayores
detalles.
Pueden verse las descripciones
detalladas de las clases de la figura 1.2.1 para más datos sobre
las funciones implementadas.
bicotiImageImplementation
bicotiImageImplementation2D
bicotiImageImplementation2DSimple
bicotiImageImplementation2DArray
bicotiImageImplementation2DSparse
bicotiImageImplementation2DByLayers
bicotiImageImplementation3D
bicotiImageImplementation3DArray
bicotiImageImplementation3DLinear